01 · Case study
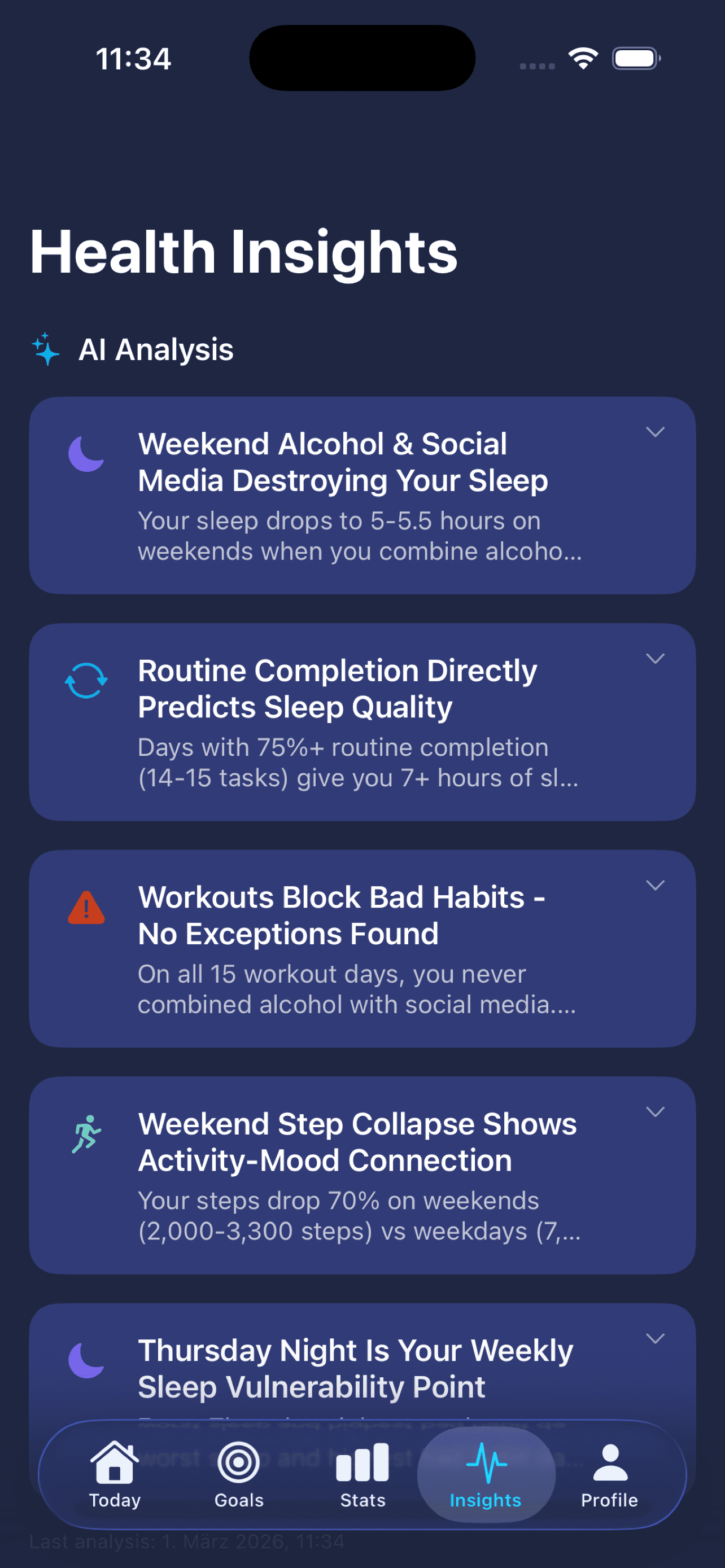
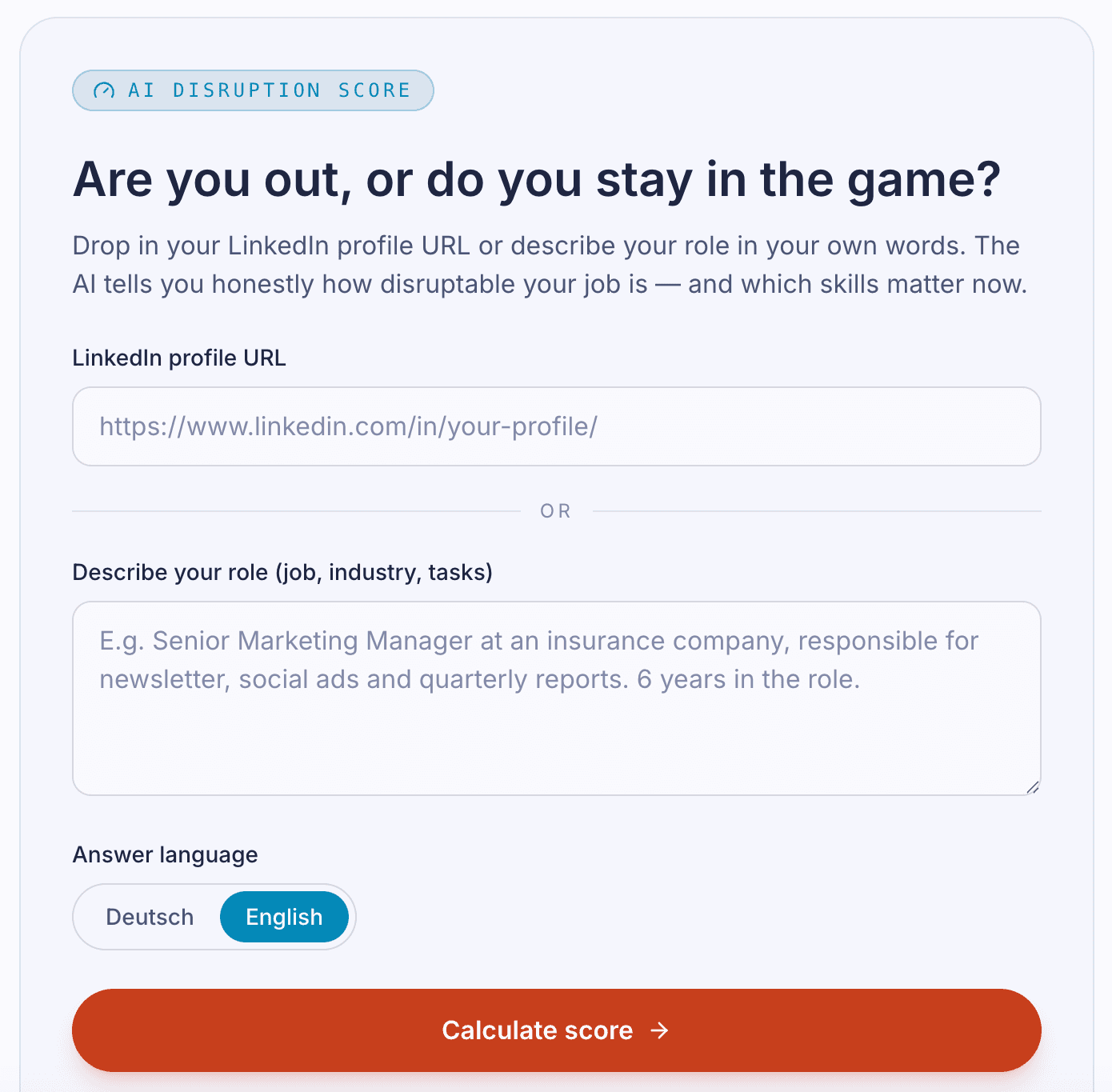
AI Disruption Score
A web tool. You drop in your LinkedIn profile, the AI tells you honestly how disruptable your job is over the next few years. Plus: which skills are about to matter and what you should learn today.
Image story

How it came about
Inspired by Anthropic's deathbyclaude.ai — that tool rates when business models and entire companies get disrupted by AI. We turned the principle onto the individual: not the business, your job. The score is meant to make it tangible that the AI shift is real and that positioning yourself now means: learn to work with AI. Concretely: build your own products.
The trick
LinkedIn profile in → Claude reads skills, industry, career phase → an unflinching verdict plus concrete skill recommendations for exactly that person. Not a generic test, a personalised analysis with recommended learning steps.
Tech stack
- Frontend
- Next.js + React (built with Claude Code)
- Backend
- LinkedIn API via RapidAPI
- AI
- Anthropic (Claude)
- Hosting
- Vercel
What we learnt
- With viral tools, the first second decides. We considered asking for job, industry, and tasks separately — cleaner for the AI, worse for conversion. The final version: drop in the LinkedIn URL, done. The AI scrapes the rest. Anyone who has to type for more than 10 seconds bounces. Slightly weaker data beats having no users at all.
- If the tool itself doesn't make money, it needs a different lever. Our setup: anyone who sees their score can have the detailed analysis sent as a PDF — in exchange for a newsletter signup. That turns a viral gimmick into a real lead machine. Important: the PDF has to deliver actual value, otherwise the lead unsubscribes immediately.
- Newsletter signups need double opt-in, or you risk a cease-and-desist. After you enter your email you get a confirmation mail with a link. Only after you click that link does your address land in the active list. Before that the address is stored with a time-limited token and deleted automatically after the deadline if no confirmation comes in. Sounds like friction, but it's mandatory and filters out bots as a bonus.