01 · Case-Study
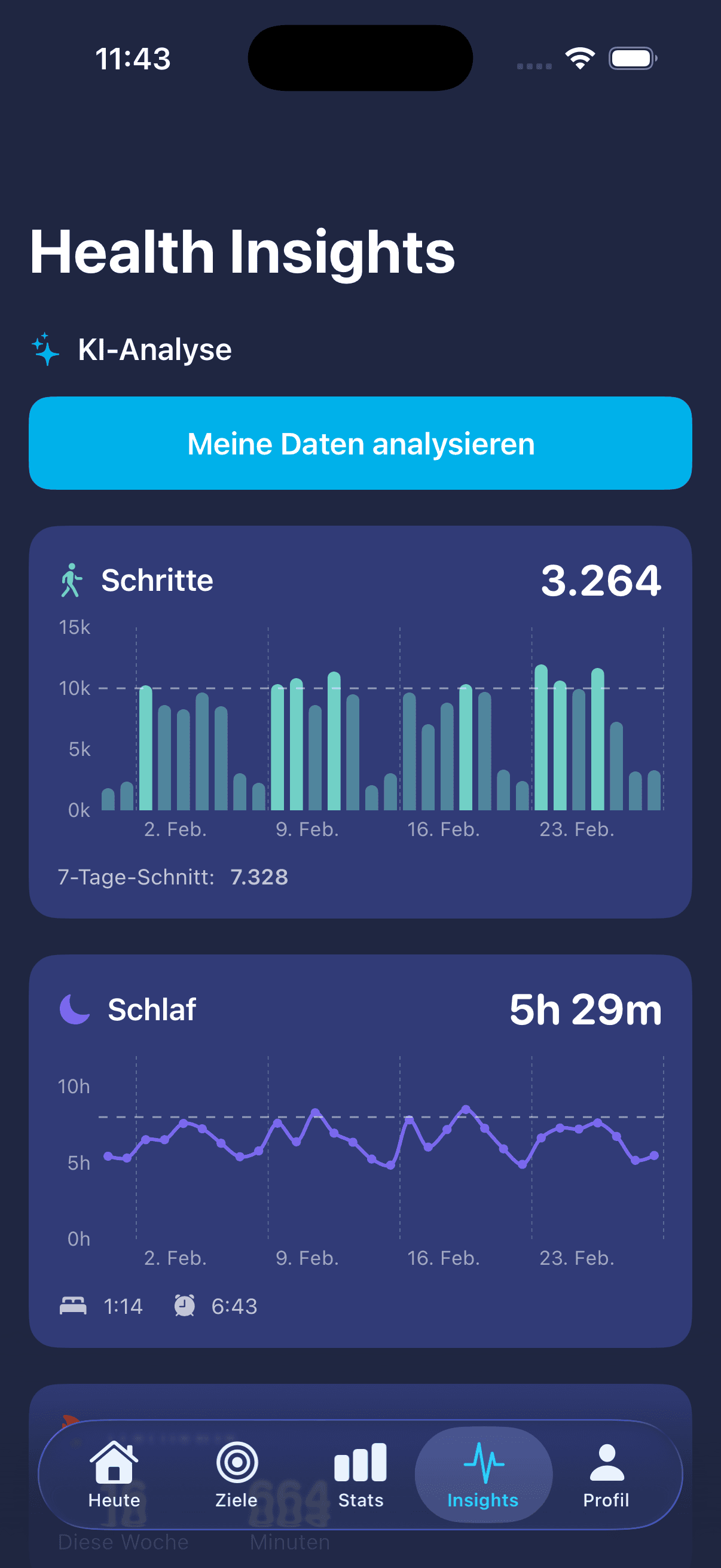
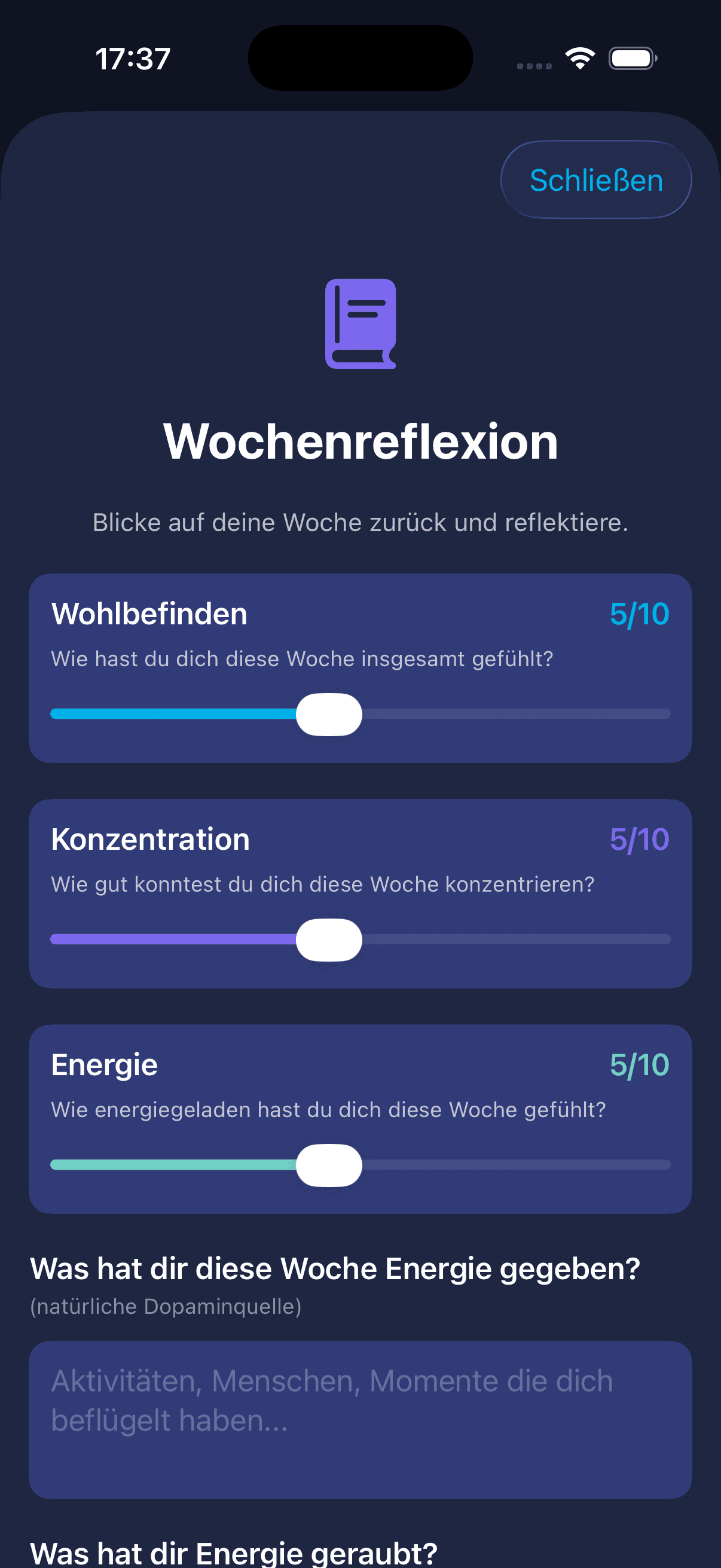
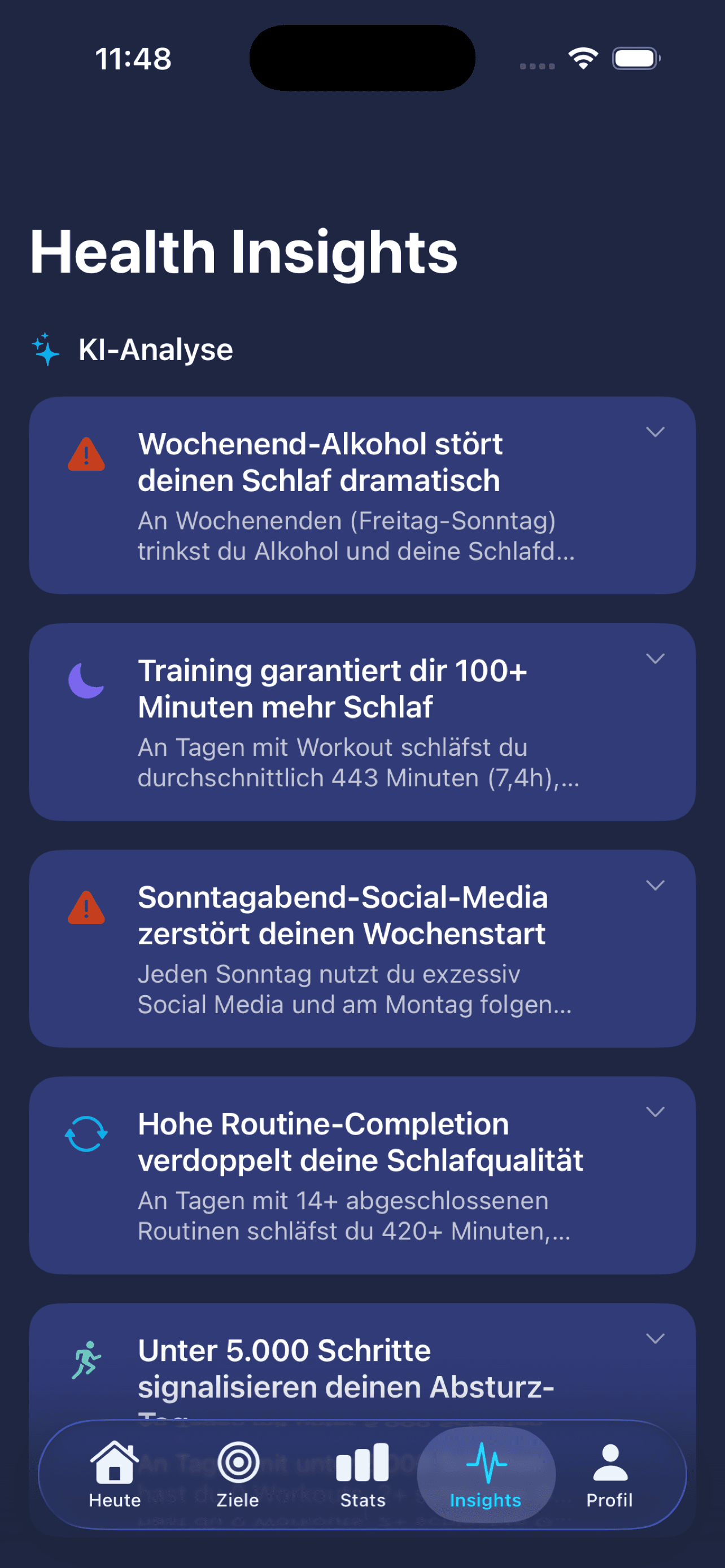
KI-Disruptions-Score
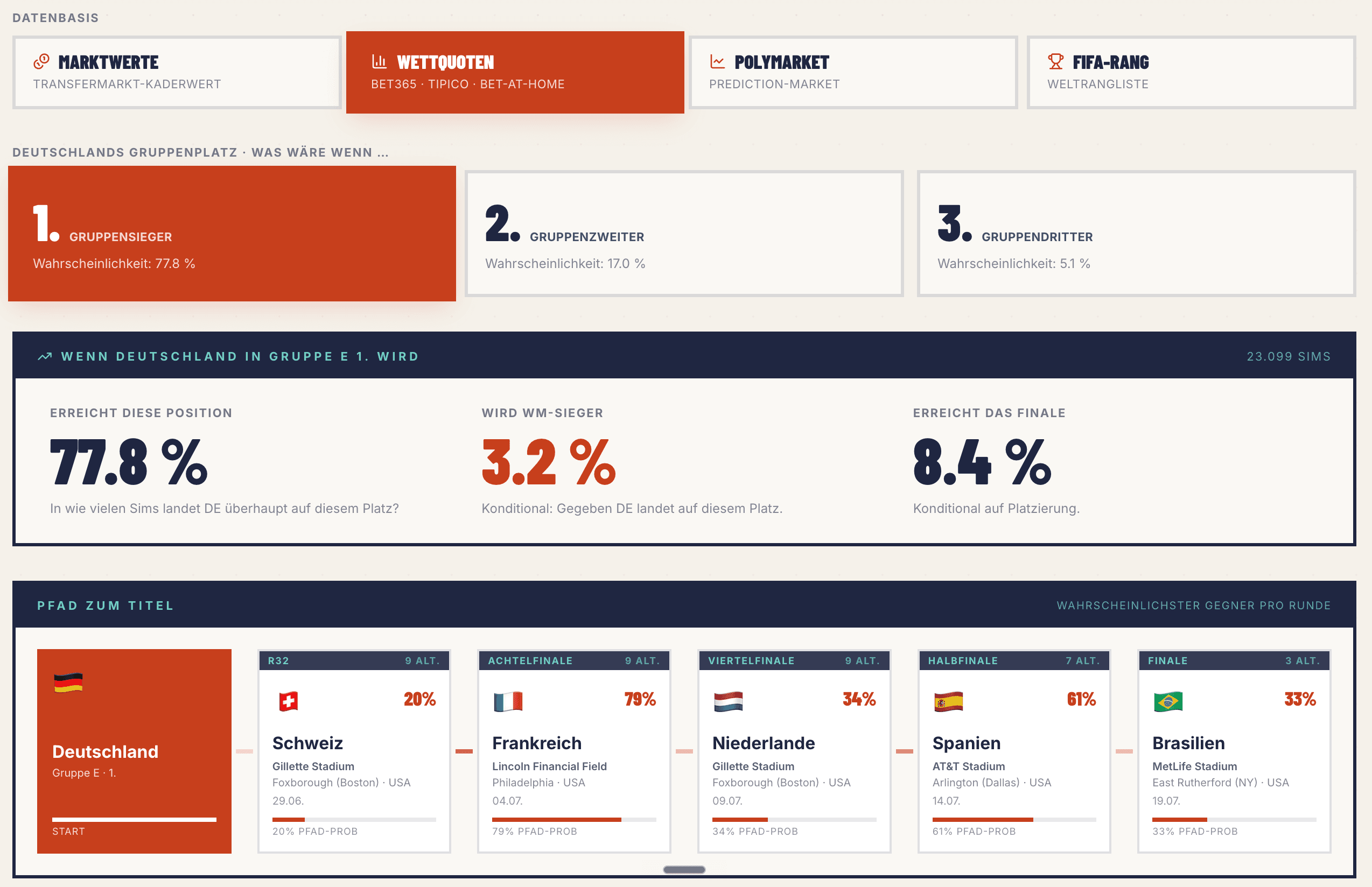
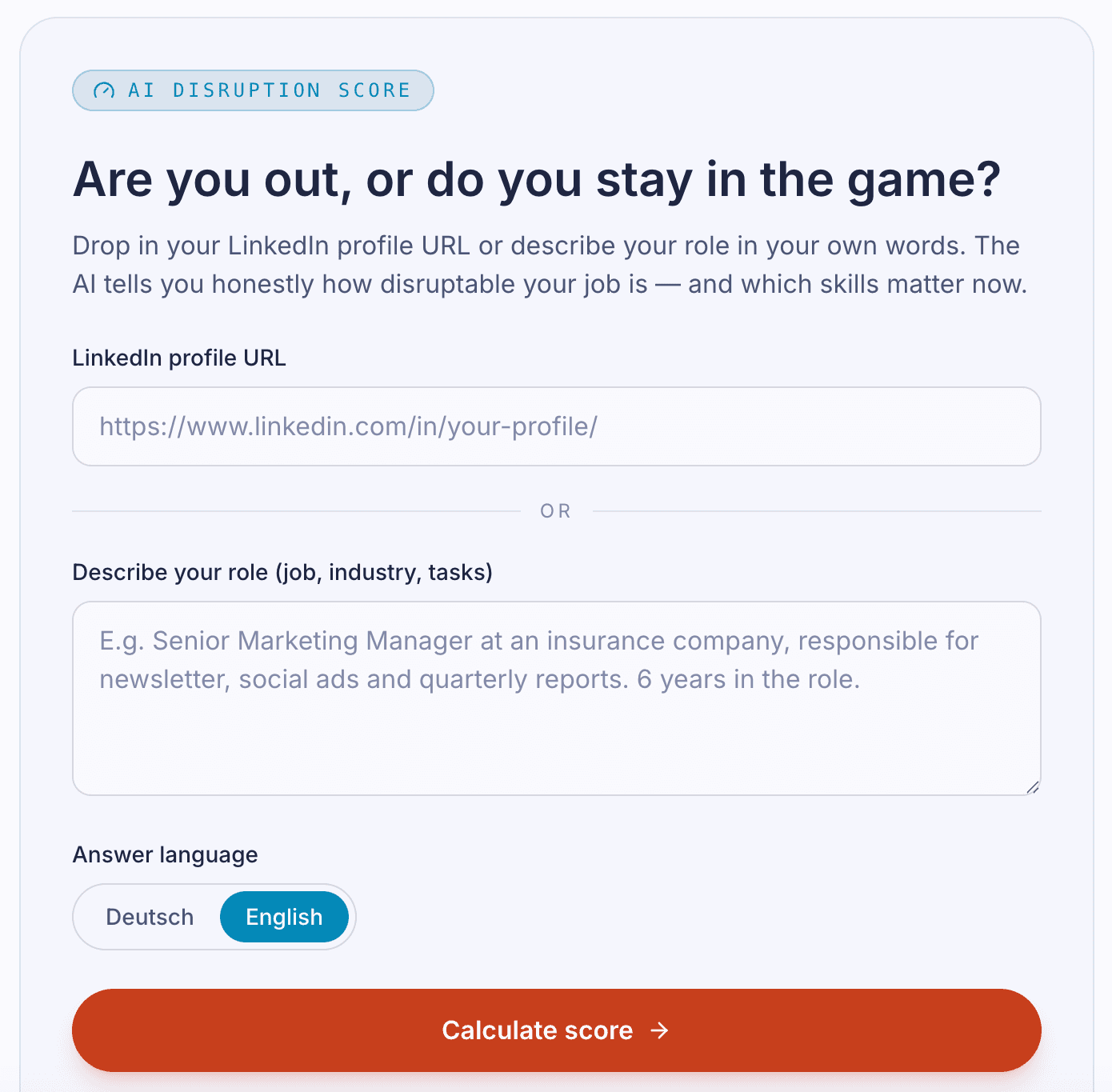
Ein Web-Tool. Du gibst dein LinkedIn-Profil rein, die KI sagt dir schonungslos ehrlich, wie disruptierbar dein Job in den nächsten Jahren ist. Plus: welche Skills relevant werden und was du heute lernen solltest.
Bild-Story

Wie es entstand
Inspiriert von Anthropics deathbyclaude.ai — das Tool bewertet, wann Geschäftsmodelle und ganze Unternehmen von KI disruptiert werden. Wir haben das Prinzip aufs Individuum gedreht: nicht das Business, sondern dein Job. Der Score soll greifbar machen, dass die KI-Revolution real ist und Positionierung jetzt heißt: lernen, mit KI zu arbeiten. Konkret: selbst Produkte bauen.
Der Kniff
LinkedIn-Profil rein → Claude liest Skills, Branche und Karrierephase → schonungslos ehrliches Urteil plus konkrete Skill-Empfehlungen für genau diese Person. Kein generischer Test, sondern personalisierte Analyse mit empfohlenen Lern-Schritten.
Tech-Stack
- Frontend
- Next.js + React (mit Claude Code gebaut)
- Backend
- LinkedIn-API via RapidAPI
- KI
- Anthropic (Claude)
- Hosting
- Vercel
Was wir gelernt haben
- Bei viralen Tools entscheidet die erste Sekunde. Wir hatten überlegt, Beruf, Branche und Aufgaben einzeln abzufragen — sauberer für die KI, schlechter für die Conversion. Die finale Variante: LinkedIn-URL rein, fertig. Die KI scrapt den Rest. Wer länger als 10 Sekunden tippen muss, springt ab. Lieber etwas schlechtere Datenbasis als gar keine Nutzer.
- Wenn das Tool selbst kein Geld bringt, muss es einen anderen Hebel haben. Bei uns: jeder, der seinen Score sieht, kann sich die Detail-Analyse als PDF zusenden lassen — gegen Newsletter-Anmeldung. So wird aus einem viralen Gimmick eine echte Lead-Maschine. Wichtig: die PDF muss wirklich Mehrwert liefern, sonst trägt der Lead sich sofort wieder aus.
- Newsletter-Einträge nur mit Double-Opt-In, sonst Abmahnung. Nach der Eingabe der Mail bekommst du eine Bestätigungs-Mail mit Link. Erst nach Klick auf den Link landest du in der aktiven Liste. Vorher wird die Adresse mit einem temporären Token gespeichert und nach Frist automatisch gelöscht, wenn keine Bestätigung kommt. Klingt nach Friction, ist aber Pflicht und filtert obendrein Bots raus.